Data Science Job Roles Explained by Dovydas Čeilutka, Our Lead of Data Science

Data science might seem like a puzzling career field for many. Even the term itself is not easy to grasp, as most people know what it means but would have a hard time explaining it. Some might think that it’s enough to run some macros on Excel and draw a nice-looking chart to call yourself a data scientist.
But it’s much more than that and can involve everything from your basic data wrangling to sophisticated machine learning methods. And although the field is relatively new, we can already see specific specializations emerging, namely the positions of Data analyst, Data engineer, Machine learning engineer and MLOps engineer.
In this article I’m going to try and explain what is that these specialists do, and, most importantly, what expectations employers have of them.
What should anyone building a career in data science know?
Over the years, I’ve seen many ways of defining data science, and the explanation that I find to be closest to the truth sounds something like this:
“Data science is the practice of using data to try to understand and solve real-world problems.“
The description is quite clear, but it’s still a bit too broad. Come to think of it, almost everyone desires to understand and solve issues analytically. Truth to be told, there is no one good definition. What I’ve noticed from interviewing candidates at Vinted is how common this uncertainty is on the current job market as well. While pretty much all data science positions require the same skill set, the level of mastery of specific technologies is what makes a candidate a good or not-so-good fit for a particular path. That is why hiring data scientists often feels like buying a box of chocolates – you never know what you’re going to get.
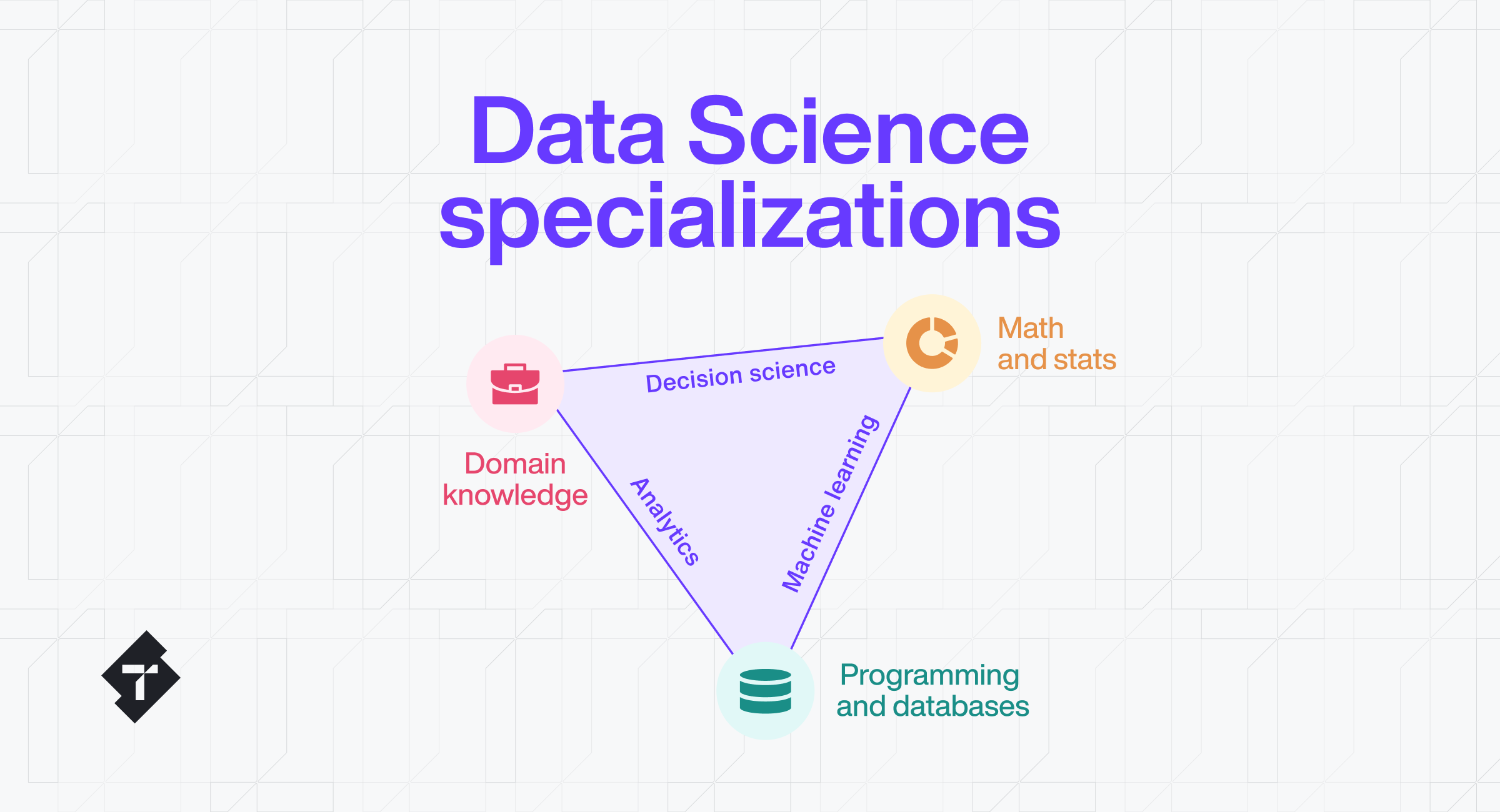
To put it simply, a data scientist must know or be good at three things – programming and databases, maths and statistics, and domain knowledge. If you were to look in-between these competencies, you’d find things like decision science, machine learning, analytics, and more. This spectrum of skills is interconnected, and different scientists can possess each of them at varying levels. This is probably why the industry has what seems like over a thousand titles to call their data scientists. Now, let’s dive deeper and see what is expected from people applying for the positions that fall into the categories of Data analyst, Data engineer, Machine learning engineer and MLOps engineer.
What does a data analyst do?
In short, data analysts are the people who analyze data to tell a story. They present actionable insights to their teams and are expected to come up with decisions using profound domain knowledge. This work requires a strong understanding of statistics and mathematics and great data wrangling skills, meaning that you have to feel comfortable importing, cleaning, and manipulating data. While modeling abilities are important for data science professionals across the board, they are indispensable for analysts, who have to make complex data easily understandable by others.

When considering tools, the dominant programming languages for data analysts are Python and R (Scala and Java also come in handy). Data analysts also use a lot of Big data technologies such as Spark, Amazon EMR or Google Dataproc services. At Vinted, for example, our data analysts use Spark daily and do a lot of decision science, mathematics, and statistics. SQL knowledge is even more beneficial than for other types of data scientists.
What is the role of a data engineer?
Data engineers design, build and operationalize data processing systems. By collecting, transforming, and publishing data, they make it available for users through a particular platform. The skills that a data engineer must have are distinct, especially looking at the high level of software engineering that these specialists demonstrate.

Here, you must possess a strong grasp on cloud technologies and software engineering especially — mostly Python and less often R, Scala, or Java. From my experience, I can tell that the choice of programming languages usually depends on the company. For example, Vinted works with Scala even though Python is more widely used in the industry. When we compare data analysts and data engineers, the way they interact with the data platforms is the main difference. Data analysts are usually the users of Big data platforms, while data engineers are the builders and maintainers. Additionally, they must know container technologies such as Docker and Kubernetes.
What is needed to be a machine learning engineer?
Machine learning engineers should be very good at building machine learning models that solve business challenges. They are responsible for the whole pipeline, as they are expected to be able to design, build and productionize on their own. To achieve this, they must have excellent modeling, software engineering, and statistics skills. Finally, they are expected to be proficient in all aspects of model architecture, data pipeline interaction, metrics interpretation and to be familiar with app development, infrastructure management, data engineering, and cybersecurity.
As most of their work revolves around machine learning frameworks, Python is a must and it’s almost non-negotiable when it comes to job requirements. Naturally, machine learning engineers use ML frameworks(scikit-learn, XGBoost) and deep learning frameworks (PyTorch, Tensorflow, MXNet), all found in only the Python ecosystem.

What is an MLOps engineer?
Generally speaking, data science as a field is still relatively new as it had appeared only around 8 or 9 years ago. Possibly the freshest specialization in the market, having popped up only a couple years ago, is machine learning ops engineering.
Modern companies do not yet know how to deal with deploying an increasing number of ML models as the ML life cycle in an enterprise setting is much more complex, in terms of needs and tooling. So, MLOps engineers provide tooling to ML engineers and data analysts to build and deploy their machine learning models successfully.
To do that, they must be very good at software engineering, Cloud technologies and DevOps (CI/CD, Monitoring), as is evident from the title. Again, Docker and Kubernetes with Python make it into their skill set list as well. Another notable technology used by MLOps is infrastructure as code, such as Terraform, intended for managing your own infrastructure independently.

What else should you know before starting a career in Data science?
Despite their differences, all four data science specializations are equally demanding and important for businesses. Currently, the industry has more job openings for data analyst and ML engineer positions compared to other specializations, but this might change. This is happening solely because these titles have been around longer, and the onboarding procedures are much clearer for employers. Also, bear in mind that getting hired in a smaller company might mean that you’d be expected to be a Jack of all trades, dealing with everything related to data. In larger companies, the common practice is to have specialized positions and extensive teams of data scientists. This is the case at Vinted as well – we have all four specializations in-house.
At this early stage of data science, a lot is evolving constantly. From taking a snapshot of the industry now, it is seen that mature companies are splitting existing specializations into even more specific ones. Still, Turing College provides a course program that gives you a strong and solid foundation on which to build on.
So, my final advice to every aspiring Data scientist would be to first of all focus on building that strong foundation. Having the basics programming and databases, maths and statistics, and domain knowledge covered will open many doors in the future, no matter where you decide to branch out to.
About the author: Dovydas Čeilutka is the Lead of Data Science on Turing College‘s Curriculum Team. He also leads the ML team at Vinted, Lithuania’s first unicorn startup, and serves as President of the Artificial Intelligence Association of Lithuania.